Welcome to Quickpickdeal! In this post, we will look into the process of inserting large volumes of random data into SQL tables for performance testing. In the next post, we will use these large tables to evaluate the performance of queries employing joins and subqueries.
How populate sql table with random data?
-- If Table [TblStudent] and [TblDonation] exists then drop the tables If (Exists (select * from information_schema.tables where table_name = 'TblStudent')) Begin Drop Table TblStudent End If (Exists (select * from information_schema.tables where table_name = 'TblDonation')) Begin Drop Table TblDonation End -- Recreate [TblStudent] and [TblDonation] tables CREATE TABLE [dbo].[TblStudent]( [Id] [int] IDENTITY(1,1) NOT NULL, [StudentName] [nvarchar](max) NOT NULL, [FatherName] [nvarchar](max) NOT NULL, CONSTRAINT [PK_TblStudent] PRIMARY KEY CLUSTERED ( [Id] ASC ) ) CREATE TABLE [dbo].[TblDonation]( [Id] [int] IDENTITY(1,1) NOT NULL, [StudentId] [int] NULL, [DonationAmount] [float] NULL, CONSTRAINT [PK_TblDonation] PRIMARY KEY CLUSTERED ( [Id] ASC ) ) GO --We are Inserting Sample dummy data into the TblStudent table Declare @Id int Set @Id = 1 While(@Id <= 200000) Begin Insert into TblStudent values('Student Name - ' + CAST(@Id as nvarchar(20)), 'Father Name - ' + CAST(@Id as nvarchar(20))) Print @Id Set @Id = @Id + 1 End -- Declare variables to hold a random StudentId from the TblStudent table, -- DonationAmount declare @RandomStudentId int declare @RandomDonationAmount float -- Declare and set variables to generate a -- random StudentId between 1 and 200000 declare @UpperLimitForStudentId int declare @LowerLimitForStudentId int set @UpperLimitForStudentId = 1 set @LowerLimitForStudentId = 200000 -- Declare and set variables to generate a -- random UnitPrice between 10 and 500 declare @UpperLimitForDonationAmount int declare @LowerLimitForDonationAmount int set @LowerLimitForDonationAmount = 10 set @UpperLimitForDonationAmount = 500 --Insert Sample data into TblDonation table Declare @Counter int Set @Counter = 1 While(@Counter <= 500000) Begin select @RandomStudentId = Round(((@UpperLimitForStudentId - @LowerLimitForStudentId) * Rand() + @LowerLimitForStudentId), 0) select @RandomDonationAmount = Round(((@UpperLimitForDonationAmount - @LowerLimitForDonationAmount) * Rand() + @LowerLimitForDonationAmount), 0) Insert into [TblDonation] values(@RandomStudentId,@RandomDonationAmount) Print @Counter Set @Counter = @Counter + 1 End
There are three parts to the SQL script.
The initial step involves verifying the existence of two tables: TblStudent and TblDonation. If these tables exist, they will be dropped.
In the subsequent phase, we will recreate these tables. Finally, random sample data will be inserted into them. Let's examine how we check for the existence of these tables and drop them.
To check for the existence of tables, I'm utilizing the system table named information_schema.tables. Let's take a look at the contents of this table by executing the query: 'SELECT * FROM information_schema.tables'.
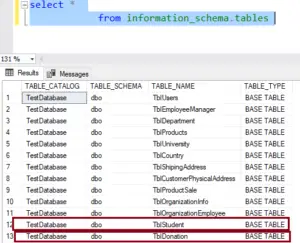
It has provided a list of table names. Where are these tables located? These tables reside within the TestDatabase because we executed the query within the context of the TestDatabase database.
We have obtained all the tables present within the TestDatabase. Here, we are checking if the table name is TblStudent. Does TblStudent exist within information_schema.tables? Yes, and we are passing this information to the Exists() function.
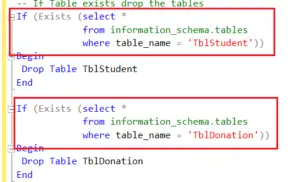
The Exists() function will return true if the table exists; otherwise, it will return false. Therefore, if this function returns true, it indicates that the table is present, and we proceed to drop it using the 'DROP TABLE TblStudent' command.
Moving on to the second part, we recreate the tables using 'CREATE TABLE TblStudent' and 'CREATE TABLE TblDonation'. An important aspect to note here is that StudentId serves as a foreign key, referencing the ID column in the TblStudent table.
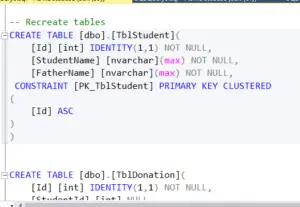
The third and final step involves inserting sample data into the tables. This process is simple and straightforward.
Looking at the TblStudent table, it consists of three columns: id, StudentName, and FatherName. The id column is an identity column, meaning we don't need to supply a value for it when inserting a row into the TblStudent table. We only need to provide values for the name and description columns, which are of type nvarchar.
The student name will be dynamically computed as 'Student1', 'Student2', 'Student3', and so on. Similarly, the father's name description will be 'Father Name 1', 'Father Name 2', and so forth.
We declare a variable of type integer, @Id, initialized to 1. While @Id is less than or equal to 200,000, indicating that we will loop through 200,000 times, we will insert 200,000 students into the TblStudent table.
The insertion statement is 'INSERT INTO TblStudent VALUES'. Firstly, we provide the value for the name column, followed by the value for the father's name column. To accomplish this, we concatenate the @Id value. Initially, @Id will be 1. We convert this to nvarchar because @Id is an integer variable. Since we are concatenating it with another string, we need to typecast it to nvarchar, as shown in the query.
So that will give value for the name column, Student Name-1, Student Name-2, etc.
And ‘Father Name – ‘ + CAST(@Id as nvarchar(20)) will give me Father Name -1, which is going to be the value for the Father Name column.
Now you execute the above query it will take approx 2-3 minutes.
Read Similar Articles
- How To Create Cursor in Sql Server With Example
- Difference between View and Indexed View or Materialized
- [Solved]-How to Upload PDF File using jquery MVC?
- What is SELF JOIN ? With Realtime Example
- Clustered and Non Clustered Index In Sql server With Real Example
- Instead Of Delete Trigger In Sql Server With Example
- Logon Trigger Example to Restrict Access In Sql Server
- Create Stored Procedure with Output and Input parameters in SQL