In this session, we will learn about what a unique index is and the difference between a unique index and a unique constraint. Before continuing with the post, I strongly recommend reading the previous post of this series.".
- How does database indexing work with real time example?
- Clustered and Non clustered index in sql server with real example
What’s a unique index?
A unique index is used to enforce the uniqueness of key values in the index. Let’s understand this with an example.
I have the sample SQL script here, which creates a table called TblUsers. If you look at the script, the ID column is marked as a primary key column.
By default, a primary key constraint creates a unique clustered index on that column if another clustered index doesn’t already exist in the table. Let’s see this in action.
CREATE TABLE [dbo].[TblUsers](
[Id] [int] Primary Key,
[Name] [nvarchar](100) NULL,
[Email] [nvarchar](100) NOT NULL,
[Gender] [int] NOT NULL,
[RewardsPoint] [decimal](18, 2) NOT NULL
)Let’s execute the SQL script to create a table, Command completed successfully.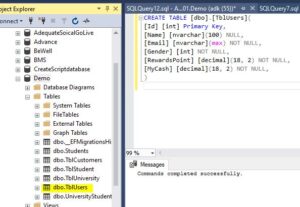
So the table should have been created since we have marked the Id column as the primary key column.
A unique clustered index should have been created on that column in the table. And obviously, to find that out, we can make use of the system stored procedure, sp_helpindex, passing in the name of the table, which will list all the indexes that are available for this table.
Execute sp_helpindex TblUsers
So let’s execute this. As you can see in the image below, we have a unique clustered index on the ID column.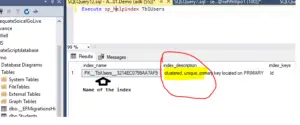 So within the object explorer, refresh the tables folder, and you should see the table. Expand that, then expand the index folder, and you should see the index that we have just created.
So within the object explorer, refresh the tables folder, and you should see the table. Expand that, then expand the index folder, and you should see the index that we have just created.
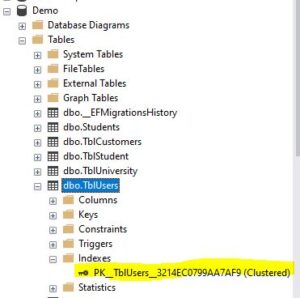
And if you look at the name, it simply says it’s a clustered index. It doesn’t specify whether it’s a unique or non-unique index.
To identify that, you can click on the index, select properties, and you should see a unique checkbox checked, which confirms that this is a unique clustered index.
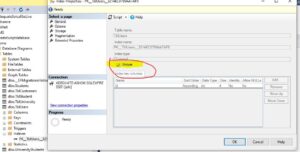
How did we get this unique clustered index?
Because we marked the Id column as the primary key, it created this unique clustered index behind the scenes. Since we marked the Id column as a primary key, there should be a primary key associated with that column.
So when I expand the Keys Folder, look at the primary key in the Keys folder. Look at the primary key and look at the index.
They’re actually the same thing, PK__TblUsers and a random number.
So in reality, the primary key constraint actually uses a unique index behind the scenes to enforce the primary key constraint.
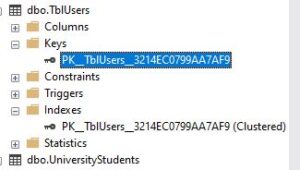
Let’s prove that. Let’s try to drop this index.
And obviously, to drop the index, we can use the drop index statement. Any time you drop an index, you’ll need to specify the table name as well.
Let’s execute the below drop script and see what happens.
drop index TblUsers.PK__TblUsers__3214EC0799AA7AF9
An explicit drop index is not allowed on this index because it’s being used for primary key constraint enforcement.
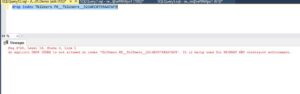
So this message proves that the primary key uses a unique index behind the scenes to enforce the constraint.
If you’re not able to drop the index using the drop index statement, you can actually do that using the object explorer.
So let’s try to delete this index from the object explorer. Right-click on the index and select delete.
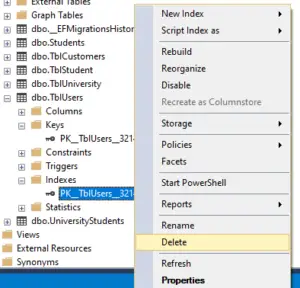
Now refresh the folder, look at what’s happening , the primary key constraint is also gone.

So now if I try to insert duplicates into the table, it will accept the duplicates values.
INSERT [dbo].[TblUsers] ([Id], [Name], [Email], [Gender], [RewardsPoint]) VALUES (1, 'Test 2', '[email protected]', 0, CAST(15.00 AS Decimal(18, 2)))
GO
INSERT [dbo].[TblUsers] ([Id], [Name], [Email], [Gender], [RewardsPoint]) VALUES (1, 'Test 3', '[email protected]', 1, CAST(31685.00 AS Decimal(18, 2)))
INSERT [dbo].[TblUsers] ([Id], [Name], [Email], [Gender], [RewardsPoint]) VALUES (1, 'aakankshi6', '[email protected]', 3, CAST(109.00 AS Decimal(18, 2)))
select * from [dbo].[TblUsers]this proves that behind the scenes, the primary key constraint actually uses a unique index to enforce that constraint.
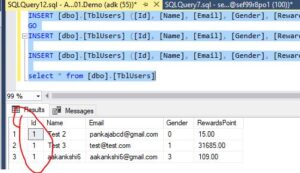
So the uniqueness of an index is not a separate index by itself. It is just a property of an index. So both clustered and non-clustered indexes can be unique.
If I want to create a unique non-clustered index, for example, let’s say I want to ensure that in tblusers, no two users can have the same name and email.
Let’s say I want to enforce that, I can actually create a unique non-clustered index in that case.
Create Unique NonClustered Index UIX_TblUsers_Name_Email
On TblUsers(Name, Email)So I’m creating a unique non-clustered index. And usually, for unique indexes, it’s better if you prefix that with UIX. So just by looking at the name, you can say that this is a unique index on TblUsers on the name and email columns.
Differences between a unique constraint and a unique index
If you want to enforce uniqueness across one or more columns, we will actually use a unique key constraint. But now we are talking about using a unique index.
So what’s the difference between them? Actually, there are no major differences between a unique constraint and a unique index.
When we add a unique constraint, a unique index gets created behind the scenes.
Let’s look at that in action. Let’s say I have the table TblCustomers, we just have a Country column on that.
Now I want to ensure that all countries are unique within the table. How do I do that? I can add a unique constraint. So let’s add a unique constraint. Obviously, to add a unique constraint, we have to alter the table.
ALTER TABLE TblCustomers
ADD CONSTRAINT UQ_TblCustomers_Country
UNIQUE NONCLUSTERED (Country)Let’s execute the command and refresh the table folder. Expand the “keys” folder, and then expand the indexes folder.
Now, look at this, we have an index created and if you look at the type of the index, it’s a non-clustered unique index.

If you want to create a clustered index, you can specify that as well
ALTER TABLE TblCustomers
ADD CONSTRAINT UQ_TblCustomers_Country
UNIQUE CLUSTERED (Country)So whether you add a unique constraint or whether you create an index, there are two ways to create a unique index: by adding a unique constraint or by using the create index statement to directly create a unique index.
So essentially, you are creating a unique constraint over a unique index. Now we know that behind the scenes, a unique index gets created. You can achieve this either through a constraint or directly using a create index statement.
When do we choose one option over the other?
Now, to make our intentions clear, create a unique constraint when data integrity is the objective. This makes the purpose of that index very clear.
In either case, the data is validated in the same manner and the query optimizer doesn’t really distinguish between a unique index that you have created using a constraint or one created manually using a create index statement.
Some useful points to remember
- We have already learned that by default, a primary key constraint creates a unique clustered index.
- We have also seen that a unique constraint creates a unique non-clustered index by default. These are only defaults and they can be changed if we wish to.
Read Similar Articles
- Difference between View and Indexed View or Materialized
- What is SELF JOIN ? With Realtime Example
- [Solved]- Find Records From One Table Which Don’t Exist In Another SQL
- How To Generate Random Data In Sql server For Performance Testing
- How to use Merge Statement in the SQL Server
- Difference Between EXCEPT and NOT IN
- How to find second or Nth Maximum Salary from Salary Table
- How to use Group By in SQL Server query?
- Simple way to Transpose Rows into columns using SQL Server