In this article, we will learn how to retrieve duplicate rows based on specific column values using SQL Server.
If you're seeking to identify duplicate rows in a database table based on certain columns, you've come to the right place.
I've been recently working on an e-commerce website project where I need to find duplicates in a SQL Server table.
There are various methods for identifying duplicate rows based on specific columns, each with different levels of efficiency, depending on the size of your database tables. In this post, we'll explore some efficient techniques to accomplish this task.
Let's consider an example: I have a table named Company_Customer in my SQL database. This table contains records of customers. Now, what I want is to select all duplicate records from the Company_Customer table.
Method-1 Using group by
select CustomerName,CustomerCity,CustomerSalary, count(*)
from Company_Customer
group by CustomerName,CustomerCity,CustomerSalary
having count(*) > 1
Generic Query
select column1,column2,column3, count(*)
from TableName
group by column1,column2,column3
having count(*) > 1Query Reseult:
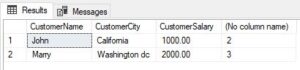
This query retrieves the CustomerName, CustomerCity, and CustomerSalary columns from the Company_Customer table and counts how many times each unique combination of these columns appears. It then filters the results to only include combinations that appear more than once, effectively identifying duplicates based on these columns. This query is useful for finding duplicate records or identifying potential data entry errors where multiple records have the same values for these columns.
- SELECT CustomerName, CustomerCity, CustomerSalary, COUNT(*):Query selects the CustomerName, CustomerCity, and CustomerSalary columns from the Company_Customer table. Additionally, it calculates the count of rows for each group of unique combinations of these columns.
- FROM Company_Customer: Specifies the table from which the data is being selected, which is Company_Customer.
- GROUP BY CustomerName, CustomerCity, CustomerSalary: This clause groups the result set by the specified columns (CustomerName, CustomerCity, CustomerSalary). This means that rows with the same combination of these columns will be grouped together.
- HAVING COUNT(*) > 1: This clause filters the grouped results to only include groups where the count of rows is greater than 1. In other words, it selects groups where there are duplicates based on the specified columns.
Method-2 Using row_number()
If you have SQL Server 2005 or lastest version, then you can use row_number() functions to return the duplicate records from the database table.
select *
from(select CustomerName
, CustomerCity
, CustomerSalary
, row_number() over (partition by CustomerName
, CustomerCity
, CustomerSalary
order by Id ) as occurrence
from Company_Customer) x
where occurrence > 1
Generic Query
select *
from(select colm1
, colm2
, colm3
, row_number() over (partition by colm1
, colm2
, colm3
order by colm1) as occurrence
from TableName) x
where occurrence > 1Query Reseult:
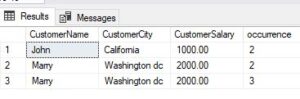
Above SQL query is querying the Company_Customer table, but it's utilizing a window function (ROW_NUMBER()) to assign a sequential number to each row within partitions defined by the combination of CustomerName, CustomerCity, and CustomerSalary.
- (SELECT CustomerName, CustomerCity, CustomerSalary, ROW_NUMBER() OVER (PARTITION BY CustomerName, CustomerCity, CustomerSalary ORDER BY Id) AS occurrence FROM Company_Customer) x: A subquery that selects CustomerName, CustomerCity, and CustomerSalary columns from the Company_Customer table. It also applies the ROW_NUMBER() window function, which assigns a unique sequential number to each row within partitions defined by CustomerName, CustomerCity, and CustomerSalary, ordered by the Id column. This effectively assigns a number to each occurrence of a unique combination of these columns.
- WHERE occurrence > 1: This filters the results from the subquery to only include rows where the occurrence number (assigned by the ROW_NUMBER() function) is greater than 1. In other words, it selects rows where there are duplicates based on the specified combination of columns.
In simpler words, this query identifies duplicate records in the Company_Customer table based on the combination of CustomerName, CustomerCity, and CustomerSalary. It assigns a sequential number to each occurrence of these combinations and then filters the results to only include occurrences where the sequential number is greater than 1, indicating duplicates. This approach is useful for identifying and handling duplicate data within the table.
Method-3 Using Rank()
Above is the easiest solution with SQL Server 2005. it will return all records record except for the first one if there are multiple occurrences.
SELECT Id
, CustomerName
, CustomerCity
, CustomerSalary
FROM
(
SELECT Id
, CustomerName
, CustomerCity
, CustomerSalary
, RANK() OVER (PARTITION BY CustomerName, CustomerCity, CustomerSalary ORDER BY Id ASC) AS [rank]
FROM Company_Customer
) a
WHERE [rank] > 1
Generic Query
SELECT Id
, cloumn1
, cloumn2
, cloumn3
FROM
(
SELECT Id
, cloumn1
, cloumn2
, cloumn3
, RANK() OVER (PARTITION BY cloumn1, cloumn2, cloumn3 ORDER BY Id ASC) AS [rank]
FROM Company_Customer
) a
WHERE [rank] > 1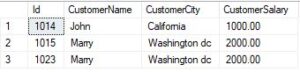
- SELECT Id, CustomerName, CustomerCity, CustomerSalary and FROM (SELECT Id, CustomerName, CustomerCity, CustomerSalary, RANK() OVER (PARTITION BY CustomerName, CustomerCity, CustomerSalary ORDER BY Id ASC) AS [rank] FROM Company_Customer) a, this is a subquery that selects Id, CustomerName, CustomerCity, and CustomerSalary columns from the Company_Customer table. It applies the RANK() window function, which assigns a ranking to each row within partitions defined by CustomerName, CustomerCity, and CustomerSalary, ordered by the Id column in ascending order.
- WHERE [rank] > 1: This filters the results from the subquery to only include rows where the rank number (assigned by the RANK() function) is greater than 1. In other words, it selects rows where there are duplicates based on the specified combination of columns.
This query identifies duplicate records in the Company_Customer table based on the combination of CustomerName, CustomerCity, and CustomerSalary. It assigns a ranking to each occurrence of these combinations and then filters the results to only include occurrences where the rank is greater than 1, indicating duplicates. This approach is useful for identifying and handling duplicate data within the table.
Method-4 Using CTE
with MYCTE as (
select row_number() over ( partition by CustomerName,CustomerCity,CustomerSalary order by Id) rown, *
from Company_Customer
)
select * from MYCTE where rown >1Above Query identifies duplicate records in the Company_Customer table based on the combination of CustomerName, CustomerCity, and CustomerSalary. It assigns a row number to each occurrence of these combinations and then selects only the rows where the row number is greater than 1, indicating duplicates. This approach is useful for identifying and handling duplicate data within the table.
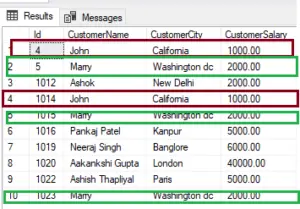
CREATE TABLE [dbo].[Company_Customer](
[Id] [int] IDENTITY(1,1) NOT NULL,
[CustomerName] [nvarchar](150) NOT NULL,
[CustomerCity] [nvarchar](500) NOT NULL,
[CustomerSalary] [decimal](18, 2) NOT NULL,
)
GO
INSERT [dbo].[Company_Customer] ([Id], [CustomerName], [CustomerCity], [CustomerSalary]) VALUES (4, 'John', 'California', CAST(1000.00 AS Decimal(18, 2)))
GO
INSERT [dbo].[Company_Customer] ([Id], [CustomerName], [CustomerCity], [CustomerSalary]) VALUES (5, 'Marry', 'Washington dc', CAST(2000.00 AS Decimal(18, 2)))
GO
INSERT [dbo].[Company_Customer] ([Id], [CustomerName], [CustomerCity], [CustomerSalary]) VALUES (1012, 'Ashok', 'New Delhi', CAST(2000.00 AS Decimal(18, 2)))
GO
INSERT [dbo].[Company_Customer] ([Id], [CustomerName], [CustomerCity], [CustomerSalary]) VALUES (1014, 'John', 'California', CAST(1000.00 AS Decimal(18, 2)))
GO
INSERT [dbo].[Company_Customer] ([Id], [CustomerName], [CustomerCity], [CustomerSalary]) VALUES (1015, 'Marry', 'Washington dc', CAST(2000.00 AS Decimal(18, 2)))
GO
INSERT [dbo].[Company_Customer] ([Id], [CustomerName], [CustomerCity], [CustomerSalary]) VALUES (1016, 'Pankaj Patel', 'Kanpur', CAST(5000.00 AS Decimal(18, 2)))
GO
INSERT [dbo].[Company_Customer] ([Id], [CustomerName], [CustomerCity], [CustomerSalary]) VALUES (1019, 'Neeraj Singh', 'Banglore', CAST(6000.00 AS Decimal(18, 2)))
GO
INSERT [dbo].[Company_Customer] ([Id], [CustomerName], [CustomerCity], [CustomerSalary]) VALUES (1020, 'Aakankshi Gupta', 'London', CAST(40000.00 AS Decimal(18, 2)))
GO
INSERT [dbo].[Company_Customer] ([Id], [CustomerName], [CustomerCity], [CustomerSalary]) VALUES (1022, 'Ashish Thapliyal', 'Paris', CAST(5000.00 AS Decimal(18, 2)))
GO
INSERT [dbo].[Company_Customer] ([Id], [CustomerName], [CustomerCity], [CustomerSalary]) VALUES (1023, 'Marry', 'Washington dc', CAST(2000.00 AS Decimal(18, 2)))
GOIf you have any doubt or query then comment.