In this session, we will learn about the advantages and disadvantages of indexes, as well as the types of queries that can benefit from indexes.
Now, before continuing with the post, I strongly recommend reading the posts below in this series.
- How does database indexing work with real time example?
- Clustered and Non clustered index with real example
- Difference between unique and non unique index
Advantages of indexes
If you look at the table TblUsers that we have here, it includes columns such as Name, Email, Gender, and RewardsPoint. The ID column is the primary key column.
And we know that when we have a primary key constraint on a table, by default, it creates a unique clustered index on that column. So on the ID column, we have a clustered index. The data is arranged in ascending order based on this column.
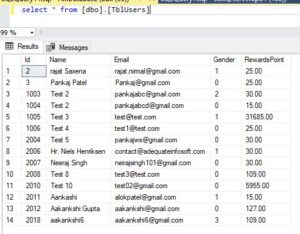
But if you look at the RewardsPoint column, it is not arranged in any specific order because the data is already arranged in ascending order based on the ID column.
Create a Non-Clustered Index on RewardsPoint Column
Create NonClustered Index IX_TblUsers_RewardsPoint
On TblUsers (RewardsPoint Asc)When you create an index on RewardsPoint Column ,internally it will look like the below image.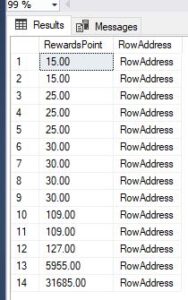
Now, you can see an index on the RewardsPoint column, and the values are arranged in ascending order.
For example, if I want to find out the user who has 127.00 Points, I would look at the row with id=12 and find the corresponding row address. Then, I can retrieve the record for Aakankshi Gupta directly using that row address.
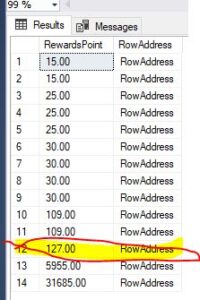
Now, let’s consider a query like `SELECT * FROM TblUsers WHERE RewardsPoint > 100 AND RewardsPoint < 500`. This query can benefit from the index on the RewardsPoint column because the RewardsPoints are arranged in ascending order.
The database engine can quickly narrow down the rows that fall within this range. It starts from the lowest value that fits the criteria (100) and retrieves all rows until it reaches the maximum value (500). Then, it retrieves the corresponding rows from the actual table using the row addresses obtained from the index.
So, SELECT statements with a WHERE clause can benefit from appropriate indexes. Similarly, DELETE and UPDATE statements can also benefit from indexes.
For instance, if I want to delete a particular record, such as users whose RewardsPoint is 127, I can efficiently execute this task by leveraging an index on the RewardsPoint column.
delete from TblUsers where RewardsPoint=127Now, let's consider a scenario where I have a million records in the table. If I need to find all the users whose RewardsPoint is 127 without an index, I would have to scan through every record sequentially. However, with an index on the RewardsPoint column, rows with the value 127 would be grouped together, making it easier to locate and delete them efficiently.
Similarly, update queries can also benefit from indexes. For instance, if I need to update the RewardsPoint of all users whose current RewardsPoint is 127, the database engine can use the index to quickly locate and update these records.
Group by clause can benefit from the index
What we're attempting to achieve here is grouping or counting the total number of users at each RewardsPoint value. For instance, we want to determine the total number of users who have 127 RewardsPoints or 100 RewardsPoints.
Select RewardsPoint, COUNT(RewardsPoint) as Total
from TblUsers
Group By RewardsPointEssentially, we're grouping users by their RewardsPoint values. Since users with similar RewardsPoint values are contiguous in the index, counting them becomes straightforward. The database engine scans the index, identifies rows with similar RewardsPoint values, counts them, and returns the results.
Disadvantages of indexes
The downside of indexes is the additional disk space they require. While clustered indexes don't need extra storage, every non-clustered index does as it's stored separately from the table. The amount of space needed depends on the table size and the number and type of columns in the index.
Although non-clustered indexes increase disk storage, the cost of storage has decreased over time. This trade-off for better application performance can be worthwhile. Additionally, if a composite index is created with multiple columns, it will require even more space.
Insert Update and delete statements can also become slow
In the previous discussion, we mentioned that inserts, updates, and deletes can benefit from indexes. However, it's important to note that these operations can also become slow. This slowdown occurs because, when performing a delete or update operation, the database needs to locate the records, which can be time-consuming.
Additionally, if a table has numerous indexes and is large in size, deleting or updating records can be further slowed down. This is because each index associated with the table needs to be updated as well.
For example, if we consider the TblUsers table with its indexes, deleting a user with a RewardsPoint equal to 127 from TblUsers would require updating all relevant indexes associated with this table.
Now, when a record is deleted from the table, it must also be removed from any associated indexes. For example, if there are ten other indexes referencing attributes like name or gender, all of these indexes must be updated accordingly.
This process of updating indexes during data manipulation operations—such as insert, update, or delete statements—can lead to performance issues, especially if there are too many indexes to update.
While indexes can assist in locating specific rows for deletion or modification, the overhead of updating numerous indexes can adversely affect the performance of these operations. Therefore, it's crucial to carefully consider the number and type of indexes used and to engage in index tuning to optimize database performance.
Read Similar Articles
- How to Create Inline Table-Valued functions in SQL server
- Difference Between Inner Join ,Left Join and Full Join in Sql
- What is difference between Subquery and Correlated subquery
- How To Write Re-Runnable SQL Server Query
- What is "Transaction" in Sql Server with example
- What are the Advantages and Disadvantages of Indexes In Sql Server?