In this article, we will learn how to perform an UPDATE statement with JOIN in SQL Server. While working on a project, I encountered a situation where I needed to write an SQL update query using joins. Now, we will explore some of the easiest techniques to accomplish this task.
Generic Syntext Query:
UPDATE tb1
SET foo = tb2.col
FROM Table1 tb1
JOIN Table2 tb2
ON tb1.col1 = tb2.colx
WHERE .your condition for updating value.Sql Query Example :
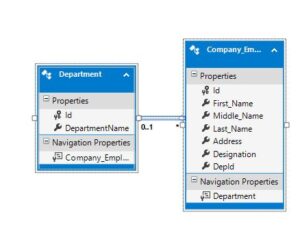
As you can see in the image below, I have created two tables: Company_Employees and Department. Company_Employees has a foreign key relationship with the Department table.
Now, I want to update the 'Designation' column with the 'DepartmentName' field from the Department table. For that, we can use the following query:
UPDATE tb1
SET Designation = tb2.DepartmentName
FROM Company_Employees tb1
JOIN Department tb2
ON tb1.DepId = tb2.Id
WHERE tb1.Id=9Cretae Script of Both Table for Practice
CREATE TABLE [dbo].[Company_Employees](
[Id] [int] IDENTITY(1,1) NOT NULL,
[First_Name] [nvarchar](200) NULL,
[Middle_Name] [nvarchar](200) NULL,
[Last_Name] [nvarchar](200) NULL,
[Address] [nvarchar](500) NULL,
[Designation] [nvarchar](200) NULL,
[DepId] [int] NULL,
CONSTRAINT [PK_TblUsers] PRIMARY KEY CLUSTERED
(
[Id] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF,
ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
CREATE TABLE [dbo].[Department](
[Id] [int] IDENTITY(1,1) NOT NULL,
[DepartmentName] [nvarchar](50) NULL,
CONSTRAINT [PK_Departments] PRIMARY KEY CLUSTERED
(
[Id] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF,
ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
Insert Query :
INSERT [dbo].[Company_Employees] ([Id], [First_Name], [Middle_Name], [Last_Name], [Address], [Designation], [DepId]) VALUES (9, 'John', 'eric', 'smith', 'Paris', 'Data Analyst', 1)
GO
INSERT [dbo].[Company_Employees] ([Id], [First_Name], [Middle_Name], [Last_Name], [Address], [Designation], [DepId]) VALUES (1010, 'Ram', 'Kumar', 'Verma', 'New Delhi', NULL, 2)
GO
GO
INSERT [dbo].[Department] ([Id], [DepartmentName]) VALUES (1, 'Data Analyst')
GO
INSERT [dbo].[Department] ([Id], [DepartmentName]) VALUES (2, ' Associate Data Engineer
')
GO
INSERT [dbo].[Department] ([Id], [DepartmentName]) VALUES (3, 'Business Intelligence Manager')
GO
INSERT [dbo].[Department] ([Id], [DepartmentName]) VALUES (4, 'Data Engineering')
Generic Query:Update t1.Column1 = value
from table_name1 as t1
inner join table_name2 as t2 on t2.ID = t1.SomeId
where t1.[column1]=value and t2.[Column1] = value;This SQL query is an UPDATE statement that modifies data in one table (table_name1) based on a condition involving another table (table_name2).
- Update t1.Column1 = value: It sets the value of Column1 in table_name1 to the specified value.
- FROM table_name1 as t1 INNER JOIN table_name2 as t2 ON t2.ID = t1.SomeId: This part of the query performs an inner join between table_name1 (aliased as t1) and table_name2 (aliased as t2) based on the condition t2.ID = t1.SomeId. This means that only rows with matching values of ID in table_name2 and SomeId in table_name1 will be included in the result set.
- WHERE t1.[column1]=value and t2.[Column1] = value: This part of the query adds additional conditions to filter the rows. It ensures that only rows where column1 in table_name1 and Column1 in table_name2 have the specified value are considered for the update operation.
This query updates Column1 in table_name1 for rows where the value of column1 in table_name1 and the value of Column1 in table_name2 are both equal to the specified value, and the ID in table_name2 matches the SomeId in table_name1. It's essentially updating records in table_name1 based on a condition involving another related table table_name2.d
Read Similar Articles
- How to create a Multi-Statement Table valued function
- What is Sql Joins? With Realtime Examples
- How to Create Stored Procedure with input parameters Step By Step
- How to Use EXCEPT Operator with an example in Sql
- What is a View? Disadvantages & Advantages of Views With an Example
- How does Recursive CTE works in Sql Server?
- Difference between Unique and Non Unique Index
- How To Get the List Of All Tables, Views, Stored Procedures