Welcome to Quickpickdeal ,in this session, we will explore the various types of indexes available in SQL Server, including clustered and non-clustered indexes, and delve into their differences.
Before proceeding further, I strongly recommend reading the previous post in this series.
The following are the different types of indexes that are available in SQL server
- Clustered
- Nonclustered
- Unique
- Filtered
- XML
- Full text
- Spatial
- Columnstore
- Index with included columns
- Index on computed columns.
In this post, we will be discussing clustered and non-clustered indexes, as well as the differences between them.
So what’s a clustered index?
A clustered index determines the physical order of data in a table. For this reason, a table can have only one clustered index. Source
We have a CREATE TABLE statement here, in which we are creating a TblUsers table. Upon close inspection, you'll notice that the Id column is designated as the primary key column.
CREATE TABLE [dbo].[TblUsers](
[Id] [int] Primary Key,
[Name] [nvarchar](100) NULL,
[Email] [nvarchar](max) NOT NULL,
[Gender] [int] NOT NULL,
[RewardsPoint] [decimal](18, 2) NOT NULL
)A primary key constraint will automatically create a clustered index on that column.
Here ID is marked as a primary key column. So when I create this table using the “create table” statement, it’s going to create a clustered index automatically on the Id column for this table.
Let’s look at this in action. Let’s execute the above query.
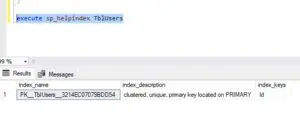
Now, let’s check in the database if it has created a clustered index on this ID automatically
How can we check that? There are two methods.
One way is to use 'sp_helpindex' to obtain information about indexes. It reveals that we have a clustered index on the ID column.
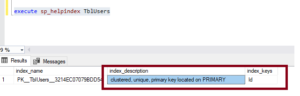
We did not create this explicitly. It was automatically created because a primary key constraint automatically generates a clustered index on that column if the table doesn’t have any existing clustered index. Upon inspection, it indicates that it's a unique clustered index.
 Learn more about unique indexs
Learn more about unique indexs
Unique index is basically used by SQL Server to enforce the uniqueness of the primary key. we have talk about unique indexes in detail in the what is a unique index post.
What is the other way of checking the indexes on this table?
The other method is to utilize the Object Explorer. Within the Object Explorer, expand the 'TblUsers' table, and then expand the 'Indexes' folder. Here, you should see the index that has just been created."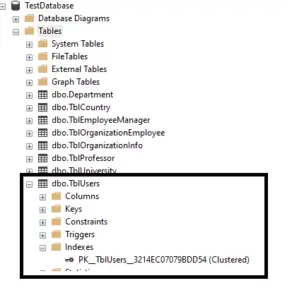 So now we have just created the table TblUsers. Let’s proceed to insert some data into that table. Below are some insert statements. In the script below, we are inserting values for id, name, email, gender, and RewardsPoint.
So now we have just created the table TblUsers. Let’s proceed to insert some data into that table. Below are some insert statements. In the script below, we are inserting values for id, name, email, gender, and RewardsPoint.
INSERT [dbo].[TblUsers] ([Id], [Name], [Email], [Gender], [RewardsPoint]) VALUES (1004, 'Test 2', '[email protected]', 0, CAST(15.00 AS Decimal(18, 2)))
GO
INSERT [dbo].[TblUsers] ([Id], [Name], [Email], [Gender], [RewardsPoint]) VALUES (1005, 'Test 3', '[email protected]', 1, CAST(31685.00 AS Decimal(18, 2)))
GO
INSERT [dbo].[TblUsers] ([Id], [Name], [Email], [Gender], [RewardsPoint]) VALUES (2018, 'aakankshi6', '[email protected]', 3, CAST(109.00 AS Decimal(18, 2)))
GO
INSERT [dbo].[TblUsers] ([Id], [Name], [Email], [Gender], [RewardsPoint]) VALUES (2008, 'Test 8', '[email protected]', 0, CAST(109.00 AS Decimal(18, 2)))
GO
INSERT [dbo].[TblUsers] ([Id], [Name], [Email], [Gender], [RewardsPoint]) VALUES (2010, 'Test 10', '[email protected]', 0, CAST(5955.00 AS Decimal(18, 2)))
GO
INSERT [dbo].[TblUsers] ([Id], [Name], [Email], [Gender], [RewardsPoint]) VALUES (2011, 'Aankashi', '[email protected]', 1, CAST(15.00 AS Decimal(18, 2)))
GO
INSERT [dbo].[TblUsers] ([Id], [Name], [Email], [Gender], [RewardsPoint]) VALUES (2012, 'Aakankshi Gupta', '[email protected]', 0, CAST(127.00 AS Decimal(18, 2)))
GO
INSERT [dbo].[TblUsers] ([Id], [Name], [Email], [Gender], [RewardsPoint]) VALUES (1006, 'Test 4', '[email protected]', 0, CAST(25.00 AS Decimal(18, 2)))
GO
INSERT [dbo].[TblUsers] ([Id], [Name], [Email], [Gender], [RewardsPoint]) VALUES (2004, 'Test 5', '[email protected]', 0, CAST(30.00 AS Decimal(18, 2)))
GO
INSERT [dbo].[TblUsers] ([Id], [Name], [Email], [Gender], [RewardsPoint]) VALUES (2006, 'Hr. Niels Henriksen', '[email protected]', 1, CAST(30.00 AS Decimal(18, 2)))
GO
INSERT [dbo].[TblUsers] ([Id], [Name], [Email], [Gender], [RewardsPoint]) VALUES (2007, 'Neeraj Singh', '[email protected]', 0, CAST(30.00 AS Decimal(18, 2)))
GO
INSERT [dbo].[TblUsers] ([Id], [Name], [Email], [Gender], [RewardsPoint]) VALUES (2, 'rajat Saxena', '[email protected]', 1, CAST(25.00 AS Decimal(18, 2)))
GO
INSERT [dbo].[TblUsers] ([Id], [Name], [Email], [Gender], [RewardsPoint]) VALUES (3, 'Pankaj Patel', '[email protected]', 0, CAST(25.00 AS Decimal(18, 2)))
GO
INSERT [dbo].[TblUsers] ([Id], [Name], [Email], [Gender], [RewardsPoint]) VALUES (1003, 'Test 2', '[email protected]', 2, CAST(30.00 AS Decimal(18, 2)))
GOHere, if you closely examine the data, you'll notice that the values for the ID column are not in sequential order.
I am intentionally, inserting them in a nonsequential order.
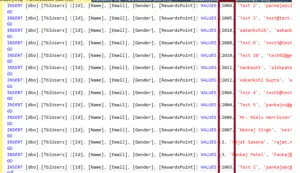
We are informed that a clustered index determines the physical order of data in a table. Additionally, in the table, we have a clustered index on the ID column.
Therefore, even if data is inserted in a nonsequential order, when you execute the query 'SELECT * FROM [dbo].[TblUsers]', the data should automatically be arranged in order.
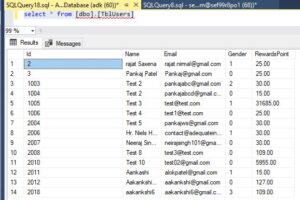
A table can only have one clustered index, but a clustered index can consist of multiple columns. When a clustered index contains multiple columns, we refer to it as a composite index. Since it’s a clustered index, we can call it a composite clustered index.
Similarly, a non-clustered index can also have multiple columns within it. In this case, we call it a composite non-clustered index.
You can think of a telephone directory as a composite index because the numbers are organized by last name first, and then, if there are similar last names for people, the data is arranged according to their first names.
Likewise, we can create a composite clustered index on the TblUsers table for the name and RewardsPoints columns.
Currently, the data is arranged in the order of the Id column because we have a clustered index on the ID column. However, instead of that, I want to create a clustered index on the name and RewardsPoints columns together. This means I want to sort the data first by name and then by RewardsPoints.
Composite cluster index
Now, let’s attempt to create a clustered index on the name and RewardsPoints columns. However, it's important to remember that there is already a clustered index on the ID column.
Create Clustered Index IX_TblUsers_Name_RewardsPoint
ON TblUsers(Name ASC,RewardsPoint DESC)Obviously, when we attempt to create this clustered index on the table, we should receive an error stating that you cannot create more than one clustered index on the TblUsers table. We need to drop the existing clustered index before creating another one.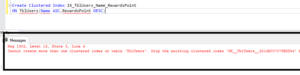
- So obviously we’ll have to drop that index.
- Go to the object explorer, expand the indexes folder.
- Right-click on the index and select delete and click.
that should delete the index.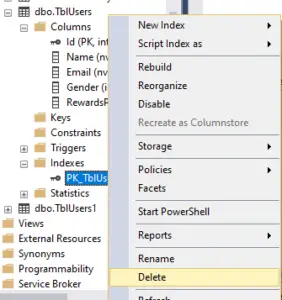
So, we have deleted the clustered index on the ID column. Now, let’s proceed to create the clustered index on the name and RewardsPoint columns.
Essentially, this is a composite clustered index because the index contains more than one column.
Keep in mind that you can only have one clustered index on a table. It's not possible to have more than one clustered index. However, it is possible for that one clustered index to have more than one column within its index keys.
Create Clustered Index IX_TblUsers_Name_RewardsPoint
ON TblUsers(Name ASC,RewardsPoint DESC)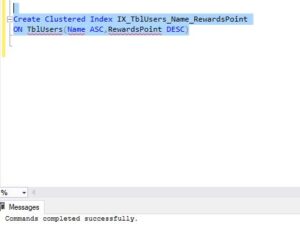
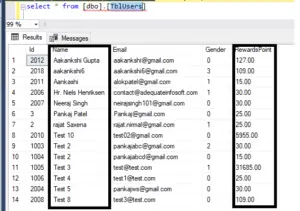
Now, let’s select the data from the TblUsers table. Before we created this index, it was arranged in ascending order based on the ID column. However, since we have now created a clustered index on the name and RewardsPoint columns, the data is now arranged in the table first by name and then by RewardsPoint within each name, in descending order.
Non clustered index
If I need to create a non-clustered index, I simply use the 'CREATE NONCLUSTERED INDEX' statement. The only difference is that instead of specifying 'CLUSTERED', I specify 'NONCLUSTERED'.
Here, if you examine the example, I am creating a non-clustered index on the name column for the TblUsers table.
Create NonClustered Index IX_TblUsers_Name_RewardsPoint
ON TblUsers(Name ASC)When we discussed clustered indexes, we understood that the data in the table is organized based on the clustered index column.
Now, when you create a non-clustered index, it's analogous to an index in a textbook.
If you examine the index in a textbook, you'll notice that it's stored separately from the data. For instance, at the beginning of the book, you have the chapter index.

Now, if I ask you to navigate to a specific chapter, you would first consult the index to find the chapter's page number. For instance, if Chapter 5 is on page number 400 according to the index, you would then turn to page 400. Hence, the index is stored separately from the data itself.
The index in a book differs from an index in a telephone directory or a dictionary. In a telephone directory or a dictionary, the data is arranged alphabetically, meaning the data itself is organized. There aren't separate index pages and data pages. However, in a book, you have distinct index pages and data pages. Similarly, a non-clustered index is analogous to a book index.
The index itself is stored separately. For example, since we have created a non-clustered index on the name column, the names are arranged in descending order, and each name is associated with a row address.
For instance, if I write a query 'SELECT * FROM [dbo].[TblUsers] WHERE name='Neeraj Singh','
What is going to happen?
It accesses the table based on the row address and retrieves the corresponding record directly.
Since the non-clustered index is stored separately from the actual table, a table can indeed have more than one non-clustered index. Similar to our book, which can have an index of chapters at the beginning and perhaps another index of common terms at the end of the book.
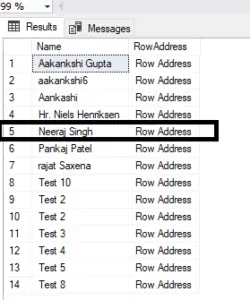
So, just like the indexes we see in a book, we can have as many indexes as we want of that kind. The same applies to non-clustered indexes.
I can create one index on the name column and another index on the gender column. Therefore, there is no restriction on how many non-clustered indexes you can have.
Difference between clustered and non clustered index with example
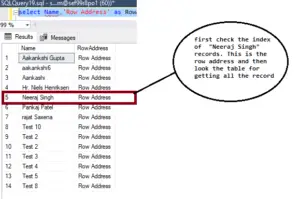
Clearly, there is one extra lookup involved if it’s a non-clustered index
However, if it’s a clustered index, then all the columns are present in the table itself, and the data in the table are arranged based on the clustered index.
Therefore, you don’t have that extra lookup. That’s why clustered indexes are slightly faster than non-clustered indexes.
Read Similar Articles
- [Solved]-Adding a column with a default value to an existing table in SQL Server
- How To Get the List Of All Tables, Views, Stored Procedures
- Why we use Stored Procedure instead of Query?
- [Solved]-How to Concatenate Text from multiple rows into a single text string in SQL server?
- How to find second or Nth Maximum Salary from Salary Table
- DDL Triggers In Sql Server with Example | Database and Server Scoped Triggers
- Pivot Rows to columns In Sql Server